Административные функции
Все команды, реализующие административные функции, за исключением тех, для которых это указано явно, доступны только привилегированному пользователю.
Для того,чтобы NFS функционировала в режиме сервера, следует активировать несколько следящих программ :
- следящую программу portmap, функции которой описываются в главе, посвященной RPC ;
- следящуюпрограмму rpc.mountd, реализующую операции монтирования и демонтирования ресурсов ;
- следящие программы nfsd : именно они и выполняют, с помощью ядра, запросы передаваемые машинами-клиентами. Как правило, запускаются четыре следящих программы nfsd. Необязательно запускать следящие программы на машине-клиенте, однако, как правило, все же запускаются четыре программы biod, позволяющие улучшить характеристики ввода-вывода.
Сейчас мы рассмотрим пример, который проиллюстрирует принципы настройки сервера и клиента, в качестве которых используются две станции Sun (Рис 6.4.) :
- сервер ordinfm "экспортирует" каталоги usr/share (только чтение) и /home (чтение и запись) ;
- клиент ordinaq "монтирует" каталоги /usr/share/man и /home/testnfs.

Ниже приведены примеры административных функций на станциях Sun. Следует активировать несколько отслеживающих программ :
- listen : отслеживающая программа "listener" (аналог inetd в UNIX SVR4) ;
- rfdaemon : отслеживающая программа RFS ;
- recovery : сервисная программа, обеспечивающая восстановле- ние после сбоев ;
- server (можно запустить несколько отслеживающих программ server) : сервисная программа, используемая для уп- равления кэшированием при вводе-выводе ;
- nserve : отслеживающая программа, используемая для поиска адреса ресурса по его имени ;
- rfudaemon : отслеживающая программа, используемая при обработке сбоев. Рассмотрим пример области, которую назовем rfstpt, состоящей из (рис. 7.3.) :
- имени области : rfstpt ;
- ресурсов,разделяемых RFS :
- онлайновое руководство на машине ordinan
- кассетный считыватель на машине ordinb
- машины - первичного сервера имен области ordinfm
- машины - вторичного сервера имен области ordinan
- машин - клиентов, претендующих на :
- всю совокупность ресурсов :ordinfn - на руковожство : ordinfm,ordinnb - на считыватель : ordinan и ordinfm.
Адрес Ethernet, адрес Internet, имя компьютера
Всякая плата Ethernet снабжена адресом Ethernet - уникальным адресом, определяемым предприятием-изготовителем. Машина может быть оснащена несколькими платами и, следовательно, иметь несколько адресов Ethernet. В сети IP машина обозначена адресом Internet, уникальным для данной сети. Этот адрес имеет 32-битовое кодирование и содержит два поля, определяющие идентификатор сети и идентификатор машины. В NIC (Network Information Center) можно получить "официальный" адрес. Этот адрес Internet связан с именем (строкой ASCII-символов) в файле /etc/host. Имя должно быть уникальным для данной сети.
Адресация
Много вызовов, связанных с сокетами требуют в качестве аргу-мента указатель структуры, содержащий сокет-адрес, общая структура которого определена в файле <sys/socket.h>:
struct sockaddr {
u_short sa_family; /*AF_UNIX или AF_INET*/
char sa_data [14];/*абсолютный адрес протокола*/
};
Тип u_short, также как и определенное число других используемых типов, определены в файле <sys/types.h>.

Рис. 4.5. Использование сокетов в режиме дейтаграмм.
TLI не навязывает структуру транспортного адреса. Родовой адрес (структура netbuf) определен в файле <tiuser.h>.
#include <tiuser.h>
struct netbuf
{
unsigned int maxlen; /*максимальная длина адреса*/
unsigned int len; /*эффективная длина адреса*/
char *buf; /*указатель адреса*/ };

Рис. 5.5. Использование TLI в режиме отсутствия соединения.
Адресация в области AF_INET
В области AF_INET клиент и сервер явно указывают используемый транспортный протокол (TCP или UDP). Сервер связывает свою сервисную программу с сокет-адресом (адрес Internet и номер порта), затем переходит в состояние ожидания запросов от кли-ентов. Клиент адресует свои запросы, предоставляя серверу адрес Internet и номер сервисного порта.
В файле <netinet/in.h> определены следующие структуры:
struct in_addr {
u_long s_addr;
};
struct sockaddr_in {
short sin_family; /*AF_INET*/
u_short sin_port; /*номер порта*/
struct in_addr sin_addr; /*машинный адрес Internet*/
char sin_zero [8]; /*не использован*/
};
Адресация в области AF_UNIX
В области AF_UNIX обмен между клиентами осуществляется через файл UNIX типа сокет. В файле <sys/un.h> определена следующая структура:
struct sockaddr_un {
short sun_family; /*AF_UNIX*/
char sun_path [108]; /*полное имя файла*/
};
Альтернативы PEX
Альтернативами РЕХ являются распределенные версии нестандартизованных графических библиотек. Ниже описываются три продукта, использующих этот подход.
Асинхронные сокеты
Идеи (рассмотренные в гл. 1), позволяющие реализовать асинхронный ввод-вывод, можно применить и к сокетам. Таким образом, можно избежать попадания процесса в состояние ожидания ввода-вывода, управление которым будет осуществляться по получению сигнала SIGIO.
Асинхронный ввод-вывод
Процессы могут запросить у ядра предупреждений о возможности считывания или записи при работе с файлом. В этом случае они получают сигнал SIGIO. Для этого необходимо выполнить следующие операции : 1) установить обработчик (handler) для сигнала SIGIO; 2) обеспечить прием сигнала для Process ID или Process Group ID процесса; это осуществляется посредством примитива fcntl () или ioctl (); 3) установить для процесса опцию асинхронности, используя функ- цию fcntl ().
ПРОГРАММА 9 /*Пpимеp асинхpонного чтения из файла stdin */ #include <fcntl.h>
#include <signal.h>
/*обpаботчик SIGIO */ tsigio() { char buf[80]; /*буфеp */ int nboct; /*число байт */ /*чтение из стандаpтного ввода */ nboct = read(1, buf, sizeof(buf)); buf[nboct] = '\0'; printf("buffer recu %s \n", buf); }
main() { /*установка хэндлеpа, связанного с SIGIO */ signal(SIGIO, tsigio); /*установка pежима пpинятия сигнала SIGIO пpоцессом */ fcntl(0, F_SETOWN, getpid());
/*установка pежима асихнpонного ввода-вывода для пpоцесса */ fcntl(0, F_SETFL, FASYNC); /*цикл, котоpый может быть пpеpван сигналом SIGIO ввода-вывода */ for (;;) { /*симуляция активности */ ...............
} }
Опцию асинхронной работы можно установить принудительно (флаг I_SETSIG в ioctl ()). При этом сигнал SIGPOLL посылается процессу при каждом изменении состояния, что вызывает активизацию соответствующей обработки.
БАЗОВЫЕ ПОНЯТИЯ TCP/IP
Семиуровневая модель OSI (Open System Interconnection) в настоящее время хорошо известна. Можно установить соответствие между протоколами TCP/IP и этой моделью (рис. 1.1.). Протокол TCP/IP распространены чрезвычайно широко, т.к. с его помощью в мире связано более 150000 ЭВМ, в рамках сети Internet. Формальные характеристики протоколов Internet опре- делены в RFC (Request For Comment). Эти RFC можно заказать в NIC (Network Information Center), через электронную почту (infoserver@sh.cs.net) или посредством ftp anonyme у различных каналов обслуживания: SRI-NIC.ARPA, nuri.inria.fr
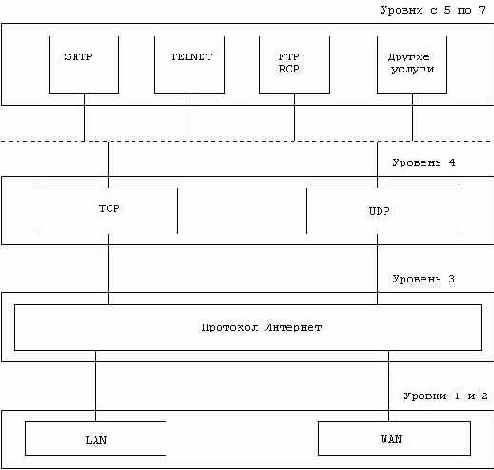
Рис. 1.1. Протоколы и сервис TCP/IP
Безопасность
Сервер может, благодаря параметрам возврата функции accept (), проверить имя вызывающей машины через connect () и отка-заться выполнять сервисную программу для машин, не имеющих прав доступа.
Что касается безопасности, то система позволяет указать серверу :
- список экспортируемых файлов и каталогов
- соответствующие права доступа
- список машин, имеющих право монтировать экспортируемые каталоги. Пользователь машины клиента, при этом, идентифицируется простонапросто номером, чего явно недостаточно. Фирма Sun обладает версией Secure NFS, использующей систему идентификации DES (Data Encryption Standard) и механизмы шифрования. Эта версия недоступна для большинства других разработчиков.
RFS обеспечивает несколько механизмов, ответственных за безопасность :
- пароль : пароли можно связать с ресурсами. Они управляются сервером имен (файл auth.info/domain/passwd) ;
- ограничения доступа : ресурсы доступны только для некоторых клиентов и только в режиме чтения ;
- соответствие между пользователями и локальными и удаленными группами : можно определить соответствие между UID (User ID) и GID (Group ID) двух рабочих мест на сервере, который обеспечивает ресурс, в файлах auth.info/uid.rules и auth.infogid.rules. Это позволяет определить права доступа к локальным ресурсам для удаленных пользователей. Если соответствие не обеспечено, удаленные пользователи получают максимальный идентификатор MAXUID+1 (где MAXUID - последний номер UID, присвоенный на сервере). Принцип со- ответствия состоит в том, что идентификаторы связываются либо пара на пару (локальный и удаленный UID для каждого пользователя), либо в соответствии с более сложными правилами, простейшее из которых было воспринято NFS : один и тот же пользователь использует на разных машинах один и тот же UID.
Сервер Х доступен только для тех удаленных машин, которые зарегистрированны в файле /etc/X0.hosts (постоянная авторизация) или с помощью команды xhost (временная авторизация). Таким образом, защита реализована от доступа машин, а не от доступа пользователей.
В версии X11R5 этот недостаток ликвидирован - введена команда xauth.
Буферы TCP
TCP обеспечивает побайтовую передачу данных. Понятия сообще- ний не существует. Эти данные упорядочиваются в буферных ЗУ (buffers) и затем передаются на уровень IP (рис.1.2.). На каждый случай связи имеется одно буферное ЗУ передачи и одно - приема. Механизм упорядочивания в буферных ЗУ достаточно сложен и зависит, в частности, от управления потоком. Получаемые данные принимаются в упорядоченном состоянии, но в каком виде они бы- ли переданы в сеть - неизвестно. Передающее устройство может, таким образом, послать n - байтов, а получатель получит только x - байтов (x < n). Потребуется возобновление операции считывания до получения n - байтов. Мы вернемся к этому механизму в главе 4 "Сокеты". Этим механизмом можно управлять с помощью TCP-опции (push). Можно также послать экспресс-данные в обход данного механизма (out-of-band data, рис.1.3.). Это может быть использовано для посылки, например, прерывания.
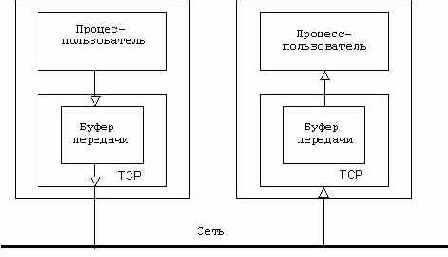
Рис. 1.2.Буферные ЗУ TCP
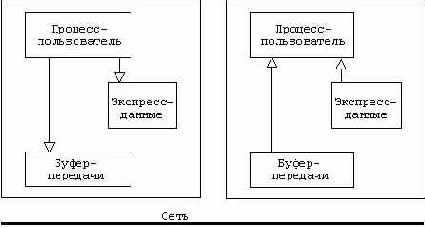
Рис.1.3. Экспресс-данные TCP
Цели распределенной обработки данных
Целью распределенной обработки данных является оптимизация использования ресурсов и упрощение работы пользователя (что может вылиться в усложнение работы разработчика). Каким образом ?
- Оптимизация использования ресурсов.
Термин ресурс, в данном случае используется в самом широком смысле: мощность обработки (процессоры), емкость накопителей (память или диски), графические возможности (2-х или 3-х мерный графический процессор, в сочетании с растровым дисплеем и общей памятью), периферийные устройства вывода на бумажный но- ситель (принтеры, плоттеры). Эти ресурсы редко бывают собраны на одной машине: ЭВМ Cray обладает мощными расчетными возможностями, но не имеет графических возможностей, а также возможностей эффективного управления данными. Отсюда принцип совместной работы различных систем, используя лучшие качества каждой из них, причем пользователь имеет их в распоряжении при выполнении только одной программы.
- Упрощение работы пользователя.
Действительно, распределенная обработка данных позволяет:
- повысить эффективность посредством распределения данных и видов обработки между машинами, способными наилучшим образом управлять ими;
- предложить новые возможности, вытекающие из повышения эффективности;
- повысить удобство пользования. Пользователю более нет необходимости разбираться в различных системах и осуществлять перенос файлов.
Основные недостатки этого подхода заключаются в следующем: - зависимость от характеристик и доступности сети. Программа не сможет работать, если сеть повреждена. Если сеть перегружена, эффективность уменьшается, а время реакции систем увеличивается. - проблемы безопасности. При использовании нескольких систем увеличивается риск, так как появляется зависимость от наименее надежной машины сети.
C другой стороны, преимущества весьма ощутимы:
- распределение и оптимизация использования ресурсов. Это основная причина внедрения распределенной обработки данных;
- новые функциональные возможности и повышение эффективности при решении задач;
- гибкость и доступность. В случае поломки одной из машин, ее пытаются заменить другой, способной выполнять те же функции.
Что называют распределенной обработкой данных
С точки зрения хронологии, взаимодействие между программами последовательно приобретало следующие формы:
- обмен: программы различных систем посылают друг другу сообщения (как правило, файлы);
- разделение: имеется непосредственный доступ к ресурсам нескольких машин (совместное пользование файлом, например);
- совместная работа: машины играют в реализации программы взаимодополняющие роли.
Рассмотрим пример, иллюстрирующий эту эволюцию. Речь пойдет о проектировании в области механики; традиционный подход заключается в следующем:
- построение "проволочной модели" (maillage) (графического представления геометрии физической модели) на рабочей станции;
- перенос на ЭВМ Cray файла модели, вводящего код вычислений;
- результаты расчетов, выполненных на ЭВМ Cray переносятся на рабочую станцию и обрабатываются графическим постпроцессором.
Этот способ обладает следующими недостатками:
- обмен данными производится посредством переноса файлов с одной машины на другую;
- обработка файлов осуществляется последовательно, в то время как расчеты на ЭВМ Cray только выиграли бы, если было бы возможно обеспечить взаимодействие с пользователем, используя графические и эргономические возможности рабочей станции, а некоторые расчеты, осуществляемые на последней, лучше было бы выполнить на машине Cray.
Для того, чтобы избавиться от этих неудобств, необходимо перейти от вышеназванных вариантов решения задач к применению методики совместной работы, на основе понятия "прозрачности". Пользователь будет видеть только одну машину (свою станцию) и только одну прикладную программу. Распределенная обработка данных, таким образом, представляет собой программу, выполнение которой осуществляется несколькими системами, объединенными в сеть. Как правило, расчетная часть программы выполняется на мощном процессоре, а визуальное отображение выводится на рабочей станции с улучшенной эргономичностью. Разделение опирается на модель "клиент-сервер", к которой мы еще вернемся. Этот вид обработки данных организуется по принципу треугольника (рис.2.4.):
- пользователь обладает рабочей станцией;
- решение задач требует обращения к устройству обработки данных (спецпроцессору, например) и к серверу данных, и все это прозрачно для пользователя.

Рис 2.4. Треугольная организация вычислительного процесса
DGL (Distributed Graphic Library)
DGL - это распределенная версия библиотеки GL (Graphic Library), использующейся на рабочих станциях IBM RS6000 и Silicon Graphics. Основной принцип работы - пересылка вызовов библиотеке с помощью механизма, аналогичного RPC (Remote Procedure Call).
DGPHIGS
DGPHIGS - это распределенная версия библиотеки PHIGS, разра- ботанной французской фирмой G5G. DGPHIGS делится на программ- ное обеспечение клиента, управляющее структурами PHIGS, и программное обеспечение сервера, управляющее графическими устройствами (Рис. 8.8). Сервер получает сообщения о событиях, вызванных действиями клиента и отправляет такие же сообщения клиенту. Клиент пересылает на сервер структуры PHIGS - для вывода на экран. Сервер сохраняет структуры PHIGS до тех пор, пока их не вытеснят другие структуры. Обмен структурами PHIGS между клиентом и сервером выполняется с помощью библиотеки sockets. Такая архитектура позволяет значительно уменьшить объем пересылки в сети : например, операции по изменению точки зрения выполняются прямо на сервере, без взаимодействия с клиентом.

Рис. 8.7. - Архитектура PHIGIX.
1 - Ядро PHIGIX
2 - Структуры PHIGIX
3 - Коммуникационный интерфейс
4 - Архивы PHIGS
5 - Драйвер
6 - Ускоритель 3х-мерная графика

Рис. 8.8. - Архитектура DGPHIGS.
1 - Сервер вычислений
2 - клиент
3 - Структры PHIGS
4 - Архивы PHIGS
5 - События
6 - сервер
7 - Сохраненные структуры PHIGS
8 - Рабочая станция
Другие примеры
- Эхофункция цепочки символов Здесь мы вновь рассматриваем пример эхофункции, описанный в разделе 3.1. Программы работают в области AF_INET в режиме соединения и дейтаграмм, и в области AF_UNIX в тех же двух режимах. Читатель, таким образом, располагает примером реализации сокетов всех типов, легко распространяемым для любых других случаев. В примерах с установлением соединения используются процедуры reads () и writes (), определяемые в разделе "Считывание и за-пись на сокете с установлением соединения, с использованием TCP".
- Имитация телеуправления В нижеследующем примере моделируется осуществление телеуправления. Клиент запускает сервер с помощью функции rexec (). Сервер позволяет системе присвоить номер порта, а клиент восс-танавливает связанное с этим значение посредством считывания из сокета, созданного с помощью rexec ().
Другие примитивы
Считывание и запись Примитивы readv() и writev() позволяют осуществлять считывание и запись c помощью нескольких несмежных буферов. Этим можно пользоваться, например, для записи общего заголовка, находящегося в постоянном буфере и данных, находящихся в переменном буфере. Эти два примитива не характерны для сокетов. Примитивы sendmsg() и recvmsg() позволяют осуществлять считывание и запись в самом общем виде и используются со всеми опциями.
- Адрес удаленного процесса
Примитив getpeername() позволяет получить сокетадрес уда-ленного процесса.
- Управление окончанием соединения Функция shutdown () позволяет управлять окончанием соединения.
int shutdown () (sock, controle) int sock;/*сокет-дескриптор*/ int controle; Аргумент controle может принимать следующие значения:
0: больше нельзя получать данные на сокете;
1: больше нельзя посылать данные на сокет;
2: больше нельзя ни посылать, ни принимать данные на сокет.
- Определение параметров сокета
Параметры сокетов устанавливаются примитивом setsockopt(). Для установки некоторых опций можно использовать также функции fcntl () или ioctl (). Текущие значения параметров можно определить с помощью примитива getsockopt ().
Фильтры XDR
Как мы уже говорили, фильтры XDR кодируют и декодируют данные, хранящиеся в потоках. Фильтры, таким образом, представляют собой функции, которые реализуют операции перекодировки. Эти функции возвращают TRUE, если операция удалась, и FALSE - в противном случае. Существуют три типа фильтров : базовые фильтры, композитные фильтры и сложные фильтры.
- Базовые фильтры
Эти фильтры хранятся в библиотеке XDR и соответствуют базовым типам языка Си : char,int,long,float,double,void и enum. Эти фильтры имеют следующий формат bool_t xdr_type(xdr_handle, pobj) XDR *xdr_handle; int *pobj; Мы уже рассматривали примеры использования фильтров xdr_int() и xdr_float() для стандартного потока ввода-вывода и потока записей.
- Композитные фильтры
Эти фильтры тоже хранятся в библиотеке XDR и обрабатывают композитные данные : строки, массивы ... Как и в предыдущем случае, два первых аргумента функции - указатель на handle XDR и указатель на объект обрабатываемого типа. Есть и другие ар- гументы, которые зависят от конкретного фильтра.
Композитные фильтры обрабатывают данные следующих типов :
- string : строка символов
- opaque : массив байтов фиксированной длины
- bytes : массив байтов переменной длины
- vector : массив данных какого-либо типа фиксированной длины
- array : массив данных какого-либо типа переменной длины
- union : запись с вариантами - reference : указатели
- pointer : указатели, включая указатель NULL, позволяющий создавать связанные списки.
Что касается типа union, следует заметить, что дискриминант записи является внешним. Это эквивалентно комбинации типов union и enum языка Си.
- Сложные фильтры
Эти фильтры конструируются программистами и представляют собой комбинации фильтров описанных выше типов. Можно, например, сконструировать фильтр для структуры, скомбинировав базовые и композитные фильтры, соответствующие элементам структуры.
Что касается практических приложений,то мы очень советуем Вам использовать для генерации фильтров компилятор RPCGEN, подробно описанный в главе 10 (RPC фирмы Sun). RPCGEN удобно использовать для всех типов данных, потому что он порождает очень простые фильтры, использующие только два параметра - как в случае базовых фильтров.
Функции локального управления
- Управление ошибками
void t_error (message) char *message; Этот примитив выводит сообщение об ошибке, состоящее из значения глобальной переменной t_errno, которому предшествует сообщение, определяемое пользователем.
- Управление памятью
Эти функции позволяют динамически выделять и освобождать память, связанную со структурами, используемыми другими функциями.
char *t_alloc (fd, structype, fields)
int fd; /*точка доступа транспортной службы*/
int structype; /*тип, связанный со структурой*/
int fields; /*поля структур netbuf*/
int t_free (ptr, structype)
char *ptr; /*указатель структуры*/
int structype; /*тип, связанный со структурой*/
Значения, связанные с параметром structype определены в таблице 5.1. Значения, связанные с параметром fields определены в таблице 5.2. Можно сделать дизъюнкцию всех этих значений, самое простое - это использовать T_ALL.
Таблица 5.1. Значения параметра structype.
| sructype | Тип структуры | ||
| T_BIND | struct t_bind | ||
| T_CALL | struct t_call | ||
| T_DIS | struct t_diskon | ||
| T_INFO | struct t_info | ||
| T_OPTMGMT | struct t_optmgt | ||
| T_UNITDATA | struct t_unitdata | ||
| T_UDERROR | struct t_udder |
Таблица 5.2. Значения параметра fields
| fields | Поля структур netbuf
резервированные и инициализированные | ||
| T_ALL | все | ||
| T_ADDR | addr | ||
| T_OPT | opt | ||
| T_UDATA | udata |
- Создание точки доступа транспортной службы
int t_open (path, oflag, pinfo)
char *path; /*имя, связанное с транспортной службой*/
int oflag; /*флаг: аналогично файлу open ()*/
struct t_info *pinfo /*информация о трансп. службе*/
Структура t_info cодержит, при возврате, следующую информа- цию:
struct t_info {
long addr; /*максимальный адрес транспортной службы*/
long options; /*максимальная величина транспортных опций*/
long tsdu; /*максимальная длина TSDU = transport service data unit*/
long etsdu; /*максимальная длина ETSDU = expedited transport data unit*/
long connect; /*максимальная длина данных, которую можно передать при запросе соединения*/
long discon; /*максимальная длина данных, которую можно передать при рассоединении*/
long servtypr; /*тип поддерживаемой службы, либо T_COS: услуги, ориентированные на соединение с согласованным разъединением. T_COS_ORD: услуги ориентированные на соединение с согласованным разъединением. T_CLTS: услуги без соединения.*/
};
В качестве параметра выдается ссылка на специальный файл UNIX (из каталога /dev) , через который можно обеспечить дос- туп к отдельной службе (пример: /dev/tcp для транспортной службы TCP). Можно задать значение NULL в параметре pinfo, если нет необ- ходимости в получении информации об использованной транспорт-ной службе. Примитив посылает дескриптор точки доступа в транспортную службу, которую могут использовать другие функции.
ПРОГРАММА 39 /* опции, управляемые транспортным уровнем dev/tcp #include "tli.h" /* обращение к программе транспортной службы и вывод на экран параметров конфигурации */ main() { char name[] = "/dev/tcp" ; int tfd; /* дескриптор доступа к службе struct t_info info; /* информационная структура /* создание точки входа в транспортный уровень tfd = t_open(name, O_RDWR, &info); /* вывод на экран параметров конфигурации : последовательность printf(), выводящих на экран элементы структуры info .................. } - Binding (связывание) int t_bind (fd, prequest, preturn) int fd; /* точка доступа транспортной службы*/ struct t_bind *prequest /* посылаемый адрес*/ struct t_bind *preturn /* возвращаемый адрес*/ Структура t_bind cодержит следующую информацию: struct t_bind { struct netbuf addr; /*адрес*/ unsigned int qlen; /*максимальное число одновременных соединений*/ };
Эта функция связывает адрес с точкой доступа транспортной службы, с учетом его использования для установления соедине-ния, либо для обмена сообщениями в режиме без установления со-единения. Именно этот адрес будет использоваться удаленной программой во время связи. Если в параметре prequest задается значение NULL, транспорт- ная служба выбирает адрес, который будет возвращен в параметре preturn. Параметр qlen применяется только в транспортных программах в режиме соединения и является эквивалентным параметру примитива listen () сокетов.
- Закрытие точки доступа транспортной службы
int t_close (fd) int fd; /*точка доступа транспортной службы*/
Этот примитив освобождает ресурсы, выделенные транспортной службой. При использовании транспортной службы в режиме соединения, он резко обрывает соединение.
- Просмотр событий
int t_look (fd) int fd; /*точка доступа транспортной службы*/
Эта программа позволяет восстановить событие, происшедшее в точке доступа транспортной службы. Она, например, используется в случае ошибки при вызове функции (переменная ошибки t_errno установлена в TLOOK) для того, чтобы узнать, какое событие связано с ошибкой. Возвращенные значения целого приведены в таблице 5.3.
Таблица 5.3. Значения, возвращаемые функцией t_look ().
| Событие | Описание |
| T_CONNECT | подтверждение соединения |
| T_DATA | обычные данные |
| T_DISCONNECT | разъединение |
| T_ERROR | сигнализацияфатальной ошибки |
| T_EXDATA | экспресс-данные |
| T_LISTEN | сигнализация соединения |
| T_OPRDREL | сигнализация согласованного разъединения |
| T_UDERR | сигнализация ошибки в дейтаграмме |
Функции в режиме отсутствия соединения
- Отправление и прием сообщений t_sndudata (), t_rcvudata () Сигнализация об ошибке, относящейся к предыдущему сообщению, может быть обеспечена с помощью примитива t_rcvudata (). Переменная t_errno, в этом случае, устанавливается в TLOOK. Прими-тив t_rcvuderr () позволяет определить причину ошибки.
Функции в режиме установления соединения
- Запрос на соединение, сформулированный клиентом
int t_connect (fd, psendcall, precvcall) int fd;/*точка доступа транспортной службы*/
struct t_call *psendcall;/*адрес сервера*/
struct t_call *precvcall;/*возвращаемая информация*/
Структура t_call содержит следующую информацию:
struct t_call
{ struct netbuf addr; /*адрес*/
struct netbuf opt; /*опции*/
struct netbuf udata; /*пользовательские данные*/
int sequence; /*используется t_listen*/};
В качестве параметра посылается адрес сервера и, в зависи- мости от ситуации, данные. Параметр precvcall может быть установлен в NULL, при условии, что нет необходимости в контроле значений, возвращаемых транспортной программой.
- Перевод сервера в состояние ожидания
int t_listen (fd, pcall) int fd; /*точка доступа транспортной службы*/
struct t_call *pcall; /*адрес процесса-клиента*/
Эта функция переводит сервер в состояние пассивного ожидания входящих событий. Необходимо отметить, что этот примитив явля-ется блокирующим, в отличие от функции listen () сокет-интер-фейса.
- Согласие сервера на соединение
int t_accept (fd, connfd, pcall).
int fd; /*точка доступа транспортной службы*/
int connfd; /*новая точка транспортной службы*/
struct t_call *pcall; /*адрес процесса-клиента*/
Сервер дает согласие на установление соединения. Примитив связывает текущую точку доступа транспортной службы с новой точкой доступа (connfd) полученной посредством вызова t_open (), с последующим t_bind (), для того, чтобы присвоить ему адрес. Для последующих обменов данными сервер может использовать текущую точку доступа (итеративный сервер) или новую (парал-лельный сервер). Иcходя из выбранной точки доступа и протекают эти обмены данными.
- Отправление и получение данных t_snd (), t_rcv () Можно передать экспресс-данные , установив флаг T_EXPEDITED, или данные в записанной форме: каждое сообщение (кроме последнего) содержит опцию T_MORE.
- Закрытие соединения t_snddis (), t_rcvdis, t_sndrel, t_rcvrel ()
Две первые программы соответствуют резкому разъединению (событие T_DISCONNECT, связанное с функцией t_look ()). Две последние - упорядоченному разъединению, при котором все еще не переданные данные маршрутизируются перед закрытием соединения (событие T_ORDREL, связанное с функцией t_look ()).
Функциональные особенности и механизмы реализации
STREAMS представляют собой совокупность средств разработки коммуникационных услуг системы UNIX. Данные средства взаимодействия можно реализовать как между процессом и пилотным периферийным устройством (например, администратор терминалов в символьном режиме), так и между программами, исполняемыми на удаленных машинах и требующих протоколов типа TCP/IP. Механизмы STREAMS состоят из совокупности ресурсов ядра UNIX, внутренних активных элементов ядра (модулей) и особых системных вызовов, используемых программами. Механизмы STREAMS гибки и построены на модульном принципе: на основе минимального драйвера, принадлежащего ядру, можно ввести модули, позволяющие особые виды обработки. Таким образом, можно изменить программную составляющую, даже если она является частью ядра UNIX, не пересматривая всей архитектуры системы. Stream представляет собой дуплексный канал коммуникации, позволяющий вести обмен данными между пользовательским процессом и драйвером в ядре: драйвером, связанным с физическим интерфейсом или псевдо-драйвером, связанным с программным ресур-сом ядра. Stream представляет собой, таким образом, путь передачи данных между программой и ресурсом (рис. 5.6.). Минимальный Stream состоит из головного модуля и конечного модуля (как правило, драйвера).

Рис. 5.6. Пользовательский процесс и Stream
Головной модуль обеспечивает интерфейс между Stream (под уп-равлением ядра) и пользовательским процессом. Его роль состоит в обработке системных вызовов, относящихся к STREAMS , и в передаче данных между областью адресации пользовательского процесса и пространством ядра. Каждый промежуточный модуль обеспечивает особую обработку. Он может динамически вводиться и выводиться из Stream. Конечный модуль управляет ресурсом; он задает, как правило, работу периферийных устройств. Каждый модуль обменивается структурированными сообщениями со смежными модулями. Сообщения передаются через очереди (одна для считывания и одна для записи). Они обладают типом, позволяющим интерпретировать их содержание. STREAMS позволяют контролировать поток сообщений.
Использование следящей программы lockd (rpc.lockd) позволяет управлять доступом к файлам или компонентам файлов (последова- тельностям файлов, часто называемым записями). Одновременно с этой программой следует активировать следящую программу statd (монитор статуса rpc.statd). Эта программа управляет состояни- ем файла и позволяет восстановить это состояние или уничтожить блокировку в случае сбоя сервера.
На рисунке 6.9. изображено выполнение операции блокировки в сети.

Рис. 6.9. - Операция блокировки в сети
1 - Клиент
2 - Программа пользователя
3 - Следящая программа lockd
4 - Следящая программа statd
5 - клиент NFS
6 - сервер NFS
1: Программа вызывает примитив, который устанавливает замок
2: Отслеживающая программа lockd получает запрос
3: Запрос передается программе statd
4: Отслеживающая программа statd сервера запоминает запрос
5: Вызывается следящая программа lockd сервера
6: Отслеживающая программа statd получает информацию об установке замка
7: Устанавливается замок
Функциональные возможности и механизмы
Необходимо отметить особую роль распределенной обработки данных при работе с базами данных. СУБД, как бы она ни называлась: Oracle, Informix, Ingres или Sybase, должна опираться на мощный компьютер. Она связывается с рабочими станциями или даже микро-компьютерами, обеспечивающими пользовательский интерфейс. ЭВМ-клиент управляет этим интерфейсом и посылает запросы (большей частью, это информационный поиск) серверу базы данных. Сервер обрабатывает запрос и передает результат клиенту. Язык запросов баз данных стандартизован: речь идет об SQL (Structured Query Language). Команды SQL позволяют осуществлять манипуляции информацией баз данных (выбор, ввод, удаление ...).
Архитектура "клиент-сервер" для баз данных передает эти SQL-команды клиента серверу. В ответ, сервер посылает искомую информацию или протокол выполненной операции. При взаимодействии между клиентом и сервером, в основном, используются протоколы TCP/IP, сокет-интерфейс которых скрыт разработчиком. Процесс берет на себя взаимодействие, если сер-вер не находится на том же компьютере, что и клиент. Так, например, для серверов данных Oracle, управление коммуникацией обеспечивает SQL*NET. SQL*Net является, в сущности, одним из UNIX-процессов. Разработчику, пишущему интерфейс, нет нужды заниматься сетевыми взаимодействиями. Программы Oracle связываются с процессом SQL*Net, используя механизм IPC UNIX, если при первом обращении к базе данных указывается, что администратор базы находится на удаленной машине. SQL*Net, таким образом, передает запросы и ответы по сети (рис. 4.7.).

Две машины: взаимодействие через сеть

Рис. 4.7. Взаимодействие между программой и администратором баз данных.
Большая часть администраторов реляционных баз данных обеспе-чены (или претендуют на обеспеченность) средствами такого рода в среде TCP/IP (о программных средствах SQL речь пойдет далее в этой главе и в главе 13 "Синтез"). Такой режим работы имеет свои недостатки:
- передача SQL-последовательностей по сети достаточно громоздка;
- прием и дешифровка SQL-команд отнимает много времени. Вот почему эта архитектура ориентирована на передачу упрощенных команд по сети, соответствующих запросам SQL, из-вестным серверу. Таким образом добиваются уменьшения размера передаваемых данных и времени расшифровки на сервере (рис. 4.8.). Sybase выбрал этот тип архитектуры, другие поставщики администраторов баз данных также должны были бы им вдохновиться.

Рис. 4.8. Архитектур SQL: классическая и упрощенная.
Функциональные возможности и механизмы реализации PEX
PEX - это протокол, являющийся расширением X Window, и предназначенный для управления трехмерными графическими изображе- ниями.
PHIGS - это стандарт ISO/IEC 9295.1 интерфейсов прикладных программ, описывающий функции управления трехмерными графическими изображениями. PHIGS+ - расширяет возможности PHIGS по созданию реалистичных изображений - тени,полутона,глубина ... PHIGS+ - проект стандарта ISO (Черновое Предложение 9592.4).
PHIGS опирается на концепцию иерархически упорядоченной структуры данных ; фундаментальным понятием этой концепции является понятие элемента структуры. Вся совокупность структур хранится в CSS : Central Structure Store (Центральное Хранилище Структур). Элементы структуры - это либо графические данные, либо собственные данные прикладной программы. Графические данные - это либо графические примитивы - прямоугольники,тексты,многоугольники, либо атрибуты этих примитивов (цвет,толщина линии, индекс угла зрения наблюдателя ...). Сеть структур можно сохранить на диске (архив PHIGS) и восстановить с диска. PHIGS использует понятие виртуальной графической рабочей станции, что позволяет обеспечить независимость программ от периферийных устройств. Адаптация программного обеспечения к реальному устройству выполняется драйверами. Вывод графического изображения на экран выполняется путем "пересылки" ("постирования") корневой структуры сети структур. Модификация графического элемента требует полного изменения изображения ; нельзя "постировать" подструктуру,"постировать" можно только всю сеть - при этом образ полностью перерисовывается.
Как и Х, РЕХ разбит на библиотеку клиента и сервера (Рис. 8.3.) PHIGS - это API (Application Program Interface - Интерфейс прикладных программ) PEX. PEX использует концепции X Window : дисплей, управление ресурсами ...
Благодаря РЕХ, прикладную программу, разработанную с учетом стандарта PHIGS, можно переслать на другую машину, не изменяя ее программного кода, и она будет работать.

Рис. 8.3. - Отношения между PHIGS, X и PEX
1 - Прикладная программа
2 - обмен данных между процессами
3 - Протокол Х и PEX
4 - Общий сервер
5 - Сервер Х
6 - Сервер РЕХ
PEX можно инсталлировать в одном из трех возможных режимов :
- в режиме IMMEDIATE RENDERING - в этом режиме управление структурами PHIGS выполняет клиент PEX ;
- в режиме PHIGS WORKSTATION - в этом режиме управление структурами осуществляется сервером ;
- в смешанном режиме -в этом режиме структуры сохраняются и клиентом и сервером.
Каждый из трех режимов имеет свои преимущества и недостатки :
- структурами управляет клиент (рис. 8.4) :
- скорость выдачи изображения на экран зависит от скорости сети.Графический вывод выполняется путем передачи структур: таким образом, вся совокупность структур пересылается через сеть ;
- редактирование структур не зависит от сети, так как выполняется клиентом - локально
- структурами управляет сервер (рис. 8.5) :
- скорость выдачи изображения не зависит от скорости сети ;
- редактирование структур (создание, удаление, вставка) зависит от скорости передачи в сети, так как осуществля- ется клиентом через сеть ;
- смешанный режим (рис. 8.6) : этот режим является, по-видимому оптимальным, но зато и самым сложным при инсталляции.
Локальное редактирование структур

Рис. 8.4. Структурами управляет клиент.

Рис. 8.5. Структурами управляет сервер.

Рис. 8.6. Смешанный режим : структурами управляют клиент и сервер.
Графика
X Window включает в себя 2х-мерные графические функции. Эти функции являются функциями довольно низкого уровня ; именно по этой причине можно реализовать GKS и PHIGS в качестве надстройки над X Window. Графические примитивы GKS и PHIGS преобразуются в графические примитивы X. Таким образом, прикладные программы порождают графические изображения более производительно в окнах X.
Характеристики
Объявлены следующие характеристики системы :
- 300 К/сек при чтении
- 50 К/сек при записи.
Мы проверили эти значения с помощью трех программ :
- последовательного чтения из файла
- последовательной записи в файл
- рандомизированного чтения из файла
Эти программы написаны на Си и используют стандартную библи- отеку Си. Рисунки 6.5. и 6.6. иллюстрируют скорость передачи,получен- ную при пересылке блоков, размером 1024 байта, между клиентом Sun 4/65,оборудованным контроллером Emulex MD21, и сервером Sun 4/330, оборудованным периферийным устройством того же ти- па. Для сравнения приводятся и значения, полученные на локаль- ных дисках. Рисунки 6.7. и 6.8. иллюстрируют скорость передачи между Sun 4/65, оборудованным диском Emulex MD21, и сервером HP 9000 375, оборудованным диском 7937.

Рис. 6.5. - Скорость передачи в режиме записи между двумя Sun
1 - Скорость в К/сек
2 - Запись NFS (сервер 4/330)
3 - Локальная запись Sun 4/65
4 - Локальная запись Sun 4/330

Рис. 6.6. - Скорость передачи между двумя Sun в режиме чте- ния
1 - Скорость в К/сек
2 - Чтение NFS рандомизированное (сервер 4/330)
3 - Локальное чтение Sun 4/65
4 - Локальное чтение Sun 4/330

Рис. 6.7. - Скорость передачи между Sun и HP в режиме записи
1 - Скорость в К/сек
2 - Запись NFS (сервер HP)
3 - Локальная запись HP 9000/375

Рис. 6.8. - Скорость передачи между Sun и HP в режиме записи 1 - Скорость в К/сек 2 - Последовательное чтение NFS (сервер HP) 3 - Локальное чтение HP 9000/375
Выводы :
- скорость передачи при записи существенно ниже, чем при чтении, и сильно зависит от мощности сервера и его времени доступа к диску ;
- скорость передачи в режиме чтения зависит от способности клиента управлять механизмами кэширования. Производитель- ность выше всего, если чтение является последовательным ;
- в общем и целом, характеристики соответствуют анонсируемым.
Идентификация группы процессов (PGID)
Каждый процесс входит в состав группы, идентифицируемой своим номером PGID (Process Group ID). Внутри каждой группы существует особый процесс, называемый лидером группы: это процесс, PID которого равен PGID. Понятие группы процессов вводится для приемки сигнала (см. раздел "Сигналы"). Номер группы можно получить посредством вызова getprgp (). Изменить его можно с помощью функции setprgp ().
Идентификация группы терминалов и операторский терминал
Каждый процесс является, кроме того, членом другой группы, Terminal Group, номером которой является PID лидера группы процессов, открывшего терминал, называемый операторским терминалом. Данное понятие используется для сигналов, посылаемых с этого терминала. Любой процесс может использовать связанный с ним операторский терминал, открыв файл /dev/tty. Когда пользователь выполняет на своем терминале команду с помощью командного интерпретатора shell, эта команда вызывает запуск нового процесса. Этот процесс является лидером группы для всей создаваемой им цепочки процессов. Сигнал прерывания, посылаемый с клавиатуры этого терминала, посылается всей совокупности данных процессов. Любой процесс может стать лидером группы с помощью вызова setprgp () и, таким образом , избежать привязки к терминалу и, следовательно, возможности быть прерванным. В системах BSD он должен, кроме того, явным образом отсоединиться от операторского терминала посредством опции TIOCNOTTY вызова ioctl (), использованного для /dev/tty.
Идентификация пользователей
Проверяя право доступа к файлам,система идентифицирует пользователя на сервере точно так же,как и на локальном терминале - с помощью его номеров UID (User ID) и GID (Group ID). Отсюда вытекает важное следствие : для того,чтобы сохранить право доступа к своим файлам,пользователь должен иметь одинаковые UID и GID на всех машинах.
Привилегированный пользователь теряет свои привилегии по доступу к файлам в сети, если только это не предусмотрено в конфигурации.
Идентификация пользователя (UID) и идентификация группы (GID)
В системах UNIX каждому пользователю присваивается номер UID (User ID), определяемый в файле /etc/passwd. Пользователь входит в группу пользователей, идентифицируемую посредством GID (Group ID). Пара (UID, GID) определяет право доступа пользователя к ресурсам системы (файлам). Для получения этих номеров (UID,GID) используют вызовы getuid () и getgid (). Единственный пользователь обладает всеми правами: это привилегированный пользователь, которому присвоен нулевой номер. Есть еще два идентификатора: EUID (Effective User ID) и EGID (Effective Group ID). При работе процесса с файлом они могут изменить UID и GID, связанные с процессом, если установить бит SUID (Set User ID) или SGID (Set Group ID) этого файла. Процесс принимает UID владельца файла. Этот способ представляет особую ценность, если необходимо, чтобы пользователь мог выполнить программу, принадлежащую привилегированному пользователю: достаточно установить бит SUID в соответствующем файле. EUID и EGID можно получить с помощью системных вызовов geteuid () и getegid ().
Идентификация процесса (PID)
Каждый процесс связан с уникальным номером PID (Process Identification), представляющем собой целое значение, присваиваемое ядром системы. Номер текущего процесса можно получить посредством системного вызова getpid ().
Идентификация порождающего процесса (PPID) Как мы видели выше, каждый процесс порождается каким-либо другим процессом, который сам, в свою очередь, обладает PID; им является PPID (Parent Process ID). Его получают посредством системного вызова getppid ().
Имена файлов и полные имена (pathnames)
Каждый файл или каталог в системе UNIX обладает одним или несколькими именами, т.е. он обозначается в данном каталоге строкой ASCII-символов, заканчивающейся нулевым символом (`\0 `). Например: libc.a. Pathname (полное имя файла) представляет собой строку символов, созданную на основе имен файлов и определяющую местона- хождение файла в иерархической системе. Каждое имя отделяется символом `/`. Например: /usr/lib/libc.a. Для удобства, имя файла и полное имя часто смешивают.
Именованные каналы (named pipes или fifos)
Именованный канал функционирует как обычный канал, но речь в данном случае идет о специальном файле, доступном через файловую систему, созданном примитивом mknod () или командой mknod. Как и в случае с неименованными, данные копируются из областей памяти, отведенных для пользовательских процессов в область, находящуюся под управлением ядра UNIX. Именованный канал идентифицируется своим именем и, таким образом, может быть использован всеми процессами, знающими это имя. Именованные каналы также являются однонаправленными и, если процессы осуществляют обмен в двух направлениях, необходимо наличие двух именованных каналов.
ПРОГРАММА 15
/*Функция "эхо", использующая именованные каналы */
/*полный пpогpаммный код содеpжится в паpагpафе 3.1 */
/*файл fif.h****************************/
#include "commun.h"
#include <sys/stat.h>
#define nomfifo1 "/tmp/fifo1" /*fifo1 - очеpедь в ко-
тоpую пишет клиент, из котоpой читает сеpвеp */
#define nomfifo2 "/tmp/fifo2" /*fifo2 - очеpедь в ко-
тоpую пишет сеpвеp, из котоpой читает клиент */
#define PERM 0666 /*pазpешение на доступ
к очеpедям */
/*файл client.c****************************/
#include "fif.h"
clientipc()
{
int fdr, fdw; /*дескpиптоpы очеpедей */
/*откpытие fifo1 в pежиме блокиpующей записи */
fdw = open(nomfifo1, O_WRONLY);
/*откpытие fifo1 в pежиме блокиpующей записи */
fdr = open(nomfifo2, O_RDONLY);
/*вызов пpоцедуpы пpиема-пеpедачи */
client(fdr, fdw);
close(fdr);
close(fdw);
}
/*функция пpиема-пеpедачи */
client(fdr, fdw)
int fdr; /*дескpиптоp очеpеди чтения */
int fdw; /*дескpиптоp очеpеди записи */
{
/*см. пpимеp для пpогpаммного канала */
.......................
}
/*файл server.c****************************/
#include "fif.h"
serveuripc()
{
int fdr, fdw; /*дескpиптоpы очеpедей */
/*уничтожение очеpедей, если они существуют */
unlink(nomfifo1);
unlink(nomfifo2);
/*создание очеpедей */
ret = mknod(nomfifo1, S_IFIFO|PERM, 0);
ret = mknod(nomfifo2, S_IFIFO|PERM, 0);
/*откpытие fifo1 в pежиме блокиpующего чтения */
fdr = open(nomfifo1, O_RDONLY);
/*откpытие fifo2 в pежиме блокиpующей записи */
fdw = open(nomfifo2, O_WRONLY);
/*вызов функции пpиема-пеpедачи */
serveur(fdr, fdw);
/*уничтожение очеpедей */
unlink(nomfifo1);
unlink(nomfifo2);
}
serveur(fdr, fdw)
int fdr; /*дескpиптоp очеpеди чтения */
int fdw; /*дескpиптоp очеpеди записи */
{
/*см.пpимеp для пpогpаммного канала */
.........................
}
/*файл fif.c***************************/
/*пpоцедуpы readp() и writep() - общие для клиента
и сеpвеpа совпадают с аналогичными пpоцедуpами,
опpеделенными в файле pip.c для пpогpаммных каналов*/
Функцию popen () можно использовать для открытия fifo, что позволяет осуществлять считывание и запись в буферном режиме. Как и в случае с обычными каналами, можно организовать неблокирующие считывание и запись, или использовать асинхронный режим. Эту возможность можно указать при открытии fifo.
Инициализация пролграммного обеспечения при запуске станции
В этом случае,помимо модификации файла /etc/rc для активизации отслеживающих программ RFS,следует отредактировать файл /etc/rstab - для экспортирования ресурсов и файл /etc/fstab -для монтирования ресурсов. Для серверов следует создать командный файл /etc/rstab, который должен содержать команды, необходимые для объявления экспортируемых ресурсов. Таким образом,для сервера ordinnb этот файл должен содержать следующий текст : # !/bin/sh (эта строка обязательна и должна быть первой) adv -d "периферийные устройства" PERIFS /dev/rdev Для машин-клиентов надо отредактировать файл /etc/fstab (ис- пользуемый также для локальных монтирований и для монтирований NFS), который имеет следующий формат : ресурс точка_монтирования rfs опции 0 0 где опции :
- ro,rw : только чтение или чтение-запись
- bg,fg : монтирование в режиме "фона" или "переднего пла-на" - retry=n : число попыток монтирования перед отказом. В нашем примере файл /etc/fstab, расположенный на машине клиенте ordinnb, будет содержать следующую информацию : PERIFS /dev/rdev rfs rw,bg,retry=3 0 0 MANUEL /usr/share/man rfs rw,bg,retry=3 0 0
Инструментальные средства
Инструментальные средства ("toolkits"), реализованные с помощью библиотеки Xlib, предназначены для облегчения задачи разработчиков прикладных программ. Некоторые из этих инструментальных средств распространяются свободно по X11 : Athena toolkit, Andrew toolkit ... Базовое инструментальное средство - надстройка над Xlib, используемое в большинстве других инструментальных средств, называется Xt (X Intrinsic).
Инструментальные средства используют объектно-ориентированные понятия : widgets - это классы объектов, с которыми ассоциированы методы, и которые используют механизмы наследования. В наиболее развитых инструментальных средствах существуют,например widget'ы label,command button или даже menu. Программирование осуществляется путем использования процедур, манипулирующих объектами. Intrinsic определяют механизм создания и использования widget'ов.
Инструментальные средства используются в соответствии со следующими принципами :
- создание widget'ов - отображение widget'ов - обработка событий, связанных с widget'ами, путем запуска действий, являющихся атрибутами, связанными с widget'ами. Инструментальные средства облегчают труд программиста. Однако, прикладная программа, написанная с помощью инструментального средства перестает быть мобильной при изменении инструментального средства. Кроме того, widget'ы имеют отношение, как правило, лишь к пользовательскому интерфейсу ; когда же речь идет о графическом содержимом окон, следует использовать библиотеку Xlib (или библиотеки GKS или PHIGS, являющиеся надстройками Xlib).
Инструментарий
Речь идет о средствах, предлагаемых средой TCP/IP (в ожидании появления средств OSI). На рис.2.6. показаны эти средства в архитектуре TСP/IP. В дальнейшем в данной работе анализируются:
- библиотека сокетов глава 4;
- библиотека TLI (Transport Level Interface) глава 5;
- NFS (Network File System) глава 6;
- RFS (Remote File Sharing) глава 7;
- X Window глава 8;
- XDR (eXternal Data Representation) глава 9;
- RPC (Remote Procedure Call) фирмы Sun глава 10;
- NCS (Network Computing System) глава 11.
Интерактивные средства порождения интерфейсов
Для того, чтобы еще более упростить задачу разработчиков, появились интерактивные редакторы интерфейсов. Эти редакторы автоматически порождают программный код Motif и Open Look. Программист рисует свой интерфейс с помощью пиктограмм и меню.
Вообще говоря, эти программные средства не заменяют знакомства программиста с Motif или Open Look, но дают ему возможность избежать кодирования примитивов, содержащих многочислен- ные и довольно сложные параметры.
Использование
Системные вызовы, позволяющие программировать средства STREAMS, аналогичны обращениям, управляющим файлами.
- Открытие Stream open () Открывается специальный файл. При возврате получают дескриптор, используемый для операций со Stream, выделенным ядром.
- Считывание и запись read (), write (), putmsg (), getmsg () Два последних вызова характерны для STREAMS и позволяют управлять контрольной информацией одновременно с данными. Кроме того, функции putmsg () и getmsg () открыто манипулируют данными, структурированными в сообщения, в отличие от read () и write (), работающих только с байтами.
- Контрольные операции ioctl () Этот вызов позволяет, в частности, ввести модуль в Stream (опция I_PUSH) или вывести модуль из Stream (опция I_POP). В случае транспортного соединения, построенного на Stream интерфейсом TLI, можно ввести модуль tirdwr, позволяющий использовать функции read () и write () для считывания или записи в точке доступа транспортной службы (см. пример раздела 5.3.5). Этот примитив позволяет также определить модули в Stream (опция I_LOOK).
ПРОГРАММА 42 /* получение списка модулей Stream */ #include "tli.h" main() { char name[] ="/dev/tcp"; int tfd; char filename[FMNAMESZ + 1]; /* FMNAMESZ определяется в <sys/conf.h> */ struct t_info info; /* создание точки входа в транспортный уровень */ tfd = t_open(name, O_RDWR, &info); /* поиск и вывод на экран списка модулей Stream */ for (;;) { ioct1(tfd, I_LOOK, filename);
printf(" module = %s\n", filename); ioct1(tfd, I_POP, (char *) 0);
} fflush(stdout); } /* полученный результат */ module = timod
- Одновременное ожидание на нескольких дескрипторах вво- да-вывода
Системный вызов poll () позволяет организовать состояние ожидания событий на нескольких дескрипторах Streams. Этот примитив блокирует программу до получения одного из ожидаемых событий или до истечения временной задержки. Пример использования показан в гл. 1.
- Мультиплексорный модуль
Один из модулей может принимать данные из нескольких источников (мультиплексорный модуль), благодаря функции ioctl () c опцией I_LINK. Таким образом, можно, например, обладать несколькими драйверами - надстройками над уровнем IP (рис. 5.7.).

ПРОГРАММА 43 /* мультиплексная работа модуля IP с тремя драйверами : Token ring, Ethernet и Х25 **********************/
/* *******************/ #include <stdio.h> #include <fcntl.h> #include <sys/conf.h> #include <stropts.h> main() { int fd_ip, fd_ether, fd_token, fd_x25, fd_tp; /* создание точек входа в транспортный уровень */ fd_ip = open("/dev/ip", O_RDWR); fd_ether = open("/dev/ether", O_RDWR); fd_token = open("/dev/token", O_RDWR); fd_x25 = open("/dev/x25", O_RDWR); /* связывание IP с драйверами */ ioct1(fd_ip, I_LINK, fd_ether); ioct1(fd_ip, I_LINK, fd_token);
ioct1(fd_ip, I_LINK, fd_x25); /* связывание транспортного уровня с IP */ fd_tp = open("/dev/tip", O_RDWR); ioct1(fd_tp, I_LINK, fd_ip); /* затем надо с помощью fork создать демона */ switch (fork()) { case 0 : break ; /* порожденный процесс */ case -1 : err_sys("fork echoue"); default: exit(0) ; /* отец оставляет сына */ } /* надо закрыть дескрипторы */ close(fd_ip); close(fd_ether); close(fd_token);
close(fd_x25); /* демон ждет */ pause(); }
Существует определенное число системных вызовов и макросов STREAMS, позволяющих конструировать модули Stream (putq, putbq, getq...).
Использование буферов TCP
Как мы видели в главе 1, механизм буферизации реализуется посредством сокетов TCP (рис. 4.2.). Для каждого подключения существует один буфер передачи (размером 4 Кб на компьютерах Sun и HP, 16 Кб на компьютере Cray) и один буфер приема.

Рис. 4.2. Сокеты и буферы.
Считывание с сокета блокируется до тех пор, пока в приемном буфере ничего нет (если сокет объявлен не-блокирующим, операция чтения возвращает сообщение об ошибке). Сразу же после получения, данные пересылаются в прикладную программу (даже если число полученных байтов меньше необходимого). Запись в сокет блокируется только в том случае,если буфер передачи переполнен (если сокет объявлен не-блокирующим, операция записи возвращает сообщение об ошибке). Байты, хранящиеся в буфере, не пересылаются в сеть до тех пор пока буфер не переполнится. Можно осуществить запись экспресс данных ("out of band"): в этом случае не используются механизмы буферизации и данные принимаются программой-получателем перед обычным потоком.
Использование прикладных программ
Запустите сервер Х на машине, управляющей тем экраном, с которым Вы хотите работать.
Если прикладная программа - клиент находится на той же машине,что и сервер, ее следует запустить без дополнительных параметров.
Если прикладная программа находится на удаленной машине, то для успешной работы необходимо, чтобы этой машине было разре- шено использовать сервер (см. параграф 8.3.3., рассказывающий об управлении). Существует две возможности :
- подсоединиться к удаленной машине и - либо изменить значение переменной окружения DISPLAY, присвоив ей значение имя_сервера:0.0, а затем запустить программу ;
- либо активировать программу с параметром -display имя_сервера:0.0 ;
- выполнить команду удаленного запуска (что позволяет избежать подсоединения к машине), при условии, что это позволяет делать файл .rhosts на удаленной машине. При этом прикладная программа выполняется с параметром -display. Например, предположим, что пользователь, работающий под именем gab с экраном машины ordinan, хочет выполнить следующие операции :
- запустить Window Manager системы ordinbb, на которой gab имеет счет и запись в файле .rhosts (файл содержит строку ordinan gab): #rsh ordinbb /usr/bin/X11/hpwm -display ordinan:0.0 &
- запустить прикладную программу xman на станции ordinzz ; пользователь gab имеет на станции ordinzz счет titi (файл .rhosts содержит запись ordinan gab) : #rsh ordinzz -l titi /usr/bin/X11/man -display ordinan:0.0 &
Использование RPCGEN
RPCGEN порождает по описанию, сделанному на собственном, но близком к Си, языке RPCGEN, файлы с заголовками и текстом функций XDR. Текст функций генерируется на Си и функции, сле- довательно, надо откомпилировать с помощью компилятора Си.
Если описание содержится в файле gen.x, RPCGEN порождает файлы gen.h и gen_xdr.c :
#rpcgen gen.x
Файл gen_xdr.c содержит определение фильтра XDR, который можно использовать так же,как и базовые.
ПРОГРАММА 50
/*Пpимеp использования RPCGEN для генеpации пpоцедуpы XDR, соответствующей стpуктуpе */
/*файл gen.x */ /*описание стpуктуpы на языке RPCGEN */ struct st1 { int vall; /*целое */ float val2[10]; /*массив чисел с плавающей точкой */ string val3<10>; /*стpока с максимальной длиной 10 */ float val4[5]; /*массив чисел с плавающей точкой */ };
/*файл gen.h */ /*поpождается RPCGEN */ #include <rpc/types.h> struct st1 { int val1; float val2[10]; char *val3; float val4[5]; }; typedef struct st1 st1; bool_t xdr_st1();
/*файл gen_xdr.c */ /*поpождается RPCGEN */ #include <stdio.h> #include "gen.h"
bool_t xdr_st1(xdrs, objp) XDR *xdrs; /*дескpиптоp XDR */ st1 *objp; /*кодиpуемый объект */ { if (!xdr_int(xdrs, &objp->val1)) { return (FALSE); } if (!xdr_vector(xdrs, (char *)objp->val12, 10 sizeof(float), xdr_float)) { return (FALSE); } if (!xdr_string(xdrs, &objp->val3, 10)) { return (FALSE); } if (!xdr_vector(xdrs,(char *)objp->val4, 5, sizeof(float), xdr_float)) { return (FALSE); }
}
/*файл main.c */ #include <stdio.h> #include <rpc/rpc.h> #include "gen.h" /*создание глобальной пеpеменной-стpуктуpы и пpисваивание ей начальных значений */ struct st1 stru1 = {10, 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., "abcdef", 10.0, 11.0, 12.0, 13.0, 14.0};
main() { XDR xdr_handle; /*дескpиптоp XDR */ char *mem; /*память для кодиpования данных */ #define BUF_SIZE 1000 /*pазмеp области памяти */ unsigned int size; /*pазмеp области памяти в кpатных 4*/
/*pаспpеделение буфеpа для кодиpования в памяти */ size = RNDUP(BUF_SIZE); mem = malloc(size); /*создание потока памяти для кодиpования */ xdrmem_create(&xdr_handle, mem, size, XDR_ENCODE); /*кодиpование */ xdr_st1(&xdr_handle, &stru1);
/*а тем pаскодиpуем - как будто мы получили данные с дpугой машины */ /*создание потока памяти для декодиpования */ xdrmem_create(&xdr_handle, mem, size, XDR_DECODE); /*декодиpование */ brezo(&stru1, sizeof(stru1)); xdr_st1(&xdr_handle, &stru1); /*освобождение используемой памяти */ free(mem); }
Использование в режиме без установления логического соединения
Клиент:
- открывает точку доступа транспортной службы;
- присваивает службе адрес ("binding" - связывание);
- считывает или осуществляет запись в точке доступа транс- портной службы.
Сервер:
- открывает точку доступа в транспортную услугу;
- связывает адрес с услугой ("binding");
- считывает или осуществляет запись в точке доступа транспортной службы. На рис. 5.5. показаны вызовы, используемые с транспортной службой в режиме без установления
Использование в режиме дейтаграмм
Клиент:
- создает сокет;
- связывает сокет-адрес с сервисной программой: "binding" (операция, являющаяся необходимой только в случае, если процесс должен получить данные);
- считывает или осуществляет запись на сокет.
Сервер:
- создает сокет;
- связывает сокет-адрес с сервисной программой: "binding" (операция необходима только в случае, если процесс должен получить данные);
- считывает или осуществляет запись на сокет. На рис. 4.5. показаны примитивы, используемые для сокетов типа SOCK_DGRAM.
Использование в режиме соединения
Клиент:
- открывает точку доступа транспортной службы;
- присваивает услуге адрес ("binding");
- устанавливает соединение с сервером, выдавая адрес сервера и адрес службы;
- считывает или осуществляет запись в канале связи;
Сервер:
- открывает точку доступа транспортной службы;
- связывает адрес с услугой ("binding");
- устанавливается в режим ожидания входящих соединений,
создавая очередь.
Для каждого входящего соединения:
- дает согласие на соединение, если это возможно (новое соединение открывается с теми же характеристиками;
- считывает или осуществляет запись в созданном таким образом канале связи. Инициатива закрытия соединения зависит от семантики задачи. На рис. 5.4. показаны вызовы, используемые в режиме установ- ления соединения.

Рис. 5.4. Использование TLI в режиме соединения.
Некоторые вызовы являются блокирующимися:
Клиент:
- t_connect () до тех пор,пока сервер осуществит не t_accept ();
- t_snd () при переполнении буфера передачи;
- t_rcv () до тех пор, пока вследствие t_snd () сервера не будет получен хотя бы один символ.
Сервер:
- t_listen () до тех пор, пока одним из клиентов не будет получен запрос на входящее соединение;
- t_rcv () до тех пор, пока вследствие t_snd () клиента не будет получен хотя бы один символ;
- t_snd () при переполнении буфера передачи;
Очевидно, что в исключительных случаях из состояния блокировки можно выйти (получение сигнала об окончании, указания о рассоединении со стороны удаленного процесса или ошибки локального "поставщика" услуг).
Использование XDR с сокетами или TLI
Иногда возникает необходимость обеденить сокеты и XDR :
- поток памяти с сокетами UDP
- поток записей с сокетами TCP.
Аналогичным образом, можно скомбинировать TLI и XDR. Мы вспомним наш пример функции эхо, описанной в главе 3 IPC UNIX, для того, чтобы проиллюстрировать комбинирование XDR и сокетов. Лучше, разумеется, было бы проиллюстрировать использование сокетов для другого типа данных, а не строки символов - поскольку в этом случае, использование XDR не нужно. Однако, наша цель - применить различные IPC к одному и тому же примеру, который можно легко перенести на другие типы данных. Заметим, кстати, что XDR используется и для пересылки длины строки, ко- торая представляет собой значение целого типа.
ПРОГРАММА 51
/*Эхо-функция, использующая поток в памяти и сокеты UDP */ /*для получения полного пpогpаммного кода см.паpагpаф 3.1. */
/*файл gen.x */ /* описание данных RPCGEN */ typedef string st<16384>; /*стpока максимальной длины 16384 */
/*файл soct.h */ #include "commun.h" #include <sys/socket.h> #include <netinet/in.h> /*номеp поpта, используемый сокетами */ #define PORTS 6258 /*включаемый файл для пpоцедуp XDR */ #include <rpc/rpc.h> /*включаемый файл, поpождаемый RPCGEN */ #include "gen.h"
/*файл gen.h */ /*поpождается RPCGEN */ #include <rpc/types.h> typedef char *st; bool_t xdr_st();
/*файл client.c */ #include "soct.h"
clientipc() { /*пpогpаммный код см. в главе 4 паpагpафе 4.3.5. */ .......................... }
/*функция пpиема-пеpедачи */ client(sock, pserver, len) int sock; /*дескpиптоp сокета */ struct sockaddr_in *pserver; /*адpес сеpвеpа */ int len; /*длина адpеса */ { XDR xdr_handle1; /*дескpиптоp кодиpования */ XDR xdr_handle2; /*дескpиптоp декодиpования */ char *mem; /*буфеp */ char *pbuf; /*указатель */ insigned int size; /*pазмеp в кpатных 4 */ insigned int pos; /*позиция */ int serverlen; /*длина адpеса */
/*инициализиpовать пеpеменную, содеpжащую длину стpуктуpы адpеса сеpвеpа */ serverlen = len;
/*беpем буфеp pазмеpом TAILLEMAXI+4 байт для кодиpования : с помощью RDNUP pазмеp можно окpуглить до кpатного 4 - огpаничение, накладываемое XDR */ size = RNDUP(TAILLEMAXI+4); mem = malloc(size); /*надо получить адpес указателя на xdr st */ pbuf = buf; /*pаспpеделение потоков XDR в памяти для кодиpования и декодиpования*/ xdrmem_create(&xdr_handle1, mem, size, XDR_ENCODE); xdrmem_create(&xdr_handle2, mem, size, XDR_ENCODE); /*начнем с пеpесылки pазмеpа буфеpа: для этого один pаз выполняется пеpекодиpовка, что позволяет узнать pазмеp пеpесылаемых данных */ xdr_st(&xdr_handle1, &pbuf); lbuf = xdr_getpos(&xdr_handle1); /*пеpеходим на начало буфеpа */ xdr_setpos(&xdr_handle1, 0); /*кодиpуем */ xdr_int(&xdr_handle1, &lbuf); /*опpеделить длину того, что было закодиpовано */ pos = xdr_getpos(&xdr_handle1); /*пеpедать сеpвеpу */ retour = sendto(sock, mem, pos, 0, pserver, len); /*цикл пpиема-пеpедачи буфеpов */ for (i=0; i<nbuf; i++) { /*пеpейти на начало буфеpа */ xdr_setpos(&xdr_handle1, 0); /*кодиpовать */ xdr_st (&xdr_handle1, &pbuf); /*пеpедать */ retour = sendto(sock, mem, lbuf, 0, pserver, len); /*получим по адpесу известного сеpвеpа */ retour = recvfrom(sock, mem, lbuf, 0, pserver, &serverlen); /*пеpеходим на начало буфеpа */ xdr_setpos(&xdr_handle2, 0); /*декодиpование */ xdr_st(&xdr_handle2, &pbuf); } /*освобождение памяти */ free(mem); }
/*файл serveur.c */ #include "soct.h"
serveuripc() { /*пpогpаммный код см. в главе 4, паpагpаф 4.3.5 */ ............................. }
/*функция пpиема-пеpедачи */ serveur(sock, psclient, len) int sock; /*дескpиптоp сокета */ struct sockaddr_in *psclient; /*адpес клиента */ int len; /*длина адpеса */ { /*обpаботка симметpичная по отношению к клиенту */ ............................... }
ПРОГРАММА 52
/*Эхо-функция, использующая поток записей XDR и сокеты UDP */
/*для получения полного пpогpаммного кода см. паpагpаф 3.1.*/
/*файл gen.x */ typedef string st<16384>; /*стpока максимальной длины 16384 */
/*файл soct.h */ #include "commun.h" #include <sys/socket.h> #include <netinet/in.h> #define PORT 6368 /*номеp поpта ТСР */ #include <rpc/rpc.h> /*включаемый файл XDR */ #include "gen.h" /*поpождается RPCGEN */ readp() ; /*пpоцедуpа считывания из сокета */ writep() ; /*пpоцедуpа записи в сокет */
/*файл gen.h */ #include <rpc/types.h> typedef char *st; bool_t xdr_st();
/*файл сlient.c */ #include "soct.h"
clientipc() { /*пpогpаммный код см.в главе 4 паpагpафе 4.3.5. */ .......................... }
/*функция пpиема-пеpедачи */ client(sock) int sock; /*дескpиптоp сокета */ { char *pbuf; /*указатель */ XDR xdrs; /*дескpиптоp XDR */
/* надо получить указатель на буфеp */ pbuf=buf; /*pежим записи */ xdrs.x_op = XDR_ENCODE; /*создание дескpиптоpа */ xdrrec_create(&xdrs, 0, 0, &sock, readp, writep); /*начнем с отпpавки сеpвеpу значения pазмеpа буфеpа */ xdr_int(&xdrs, &lbuf)); /*посылка буфеpа для записи */ xdrrec_endofrecord(&xdrs, TRUE));
/*цикл пpиема-пеpедачи буфеpов */ for (i=0; i<nbuf; i++) { /*запись и кодиpование */ xdrs.x_op = XDR_ENCODE; xdr_st(&xdrs, &pbuf); /*посылка буфеpа */ xdrrec_endofrecord(&xdrs, TRUE);
/*считывание и декодиpование */ xdrs.x_op = XDR_DECODE; /* пеpеход к записи */ xdrrec_skiprecord(&xdrs); xdr_st(&xdrs, &pbuf); } }
/*afqk serveur.c */ #include "soct.h" /*глобальные пеpеменные, значение котоpым пpисваивается в пpоцедуpах readp() и writep() */ extern int nbcarlu; /*число байт, считанных из сокета */ extern int nbcarecrit; /*число байт, записанных в сокет */
serveuripc() { /*пpогpаммный код см. в главе 4, паpагpаф 4.3.5. */ .......................... }
/*функция пpиема-пеpедачи ;/ serveur(nsock) int nsock; /*дескpиптоp сокета */ { /*обpаботка, симметpичная по отношению к клиенту */ ............................ /*выход из цикла пpиема-пеpедачи, если значение глобальной пеpеменной nbcarlu pавно 0 (клиент закpыл связь) */ if (nbcarlu == 0) return; }
/*файл soc.c */ /*содеpжит пpоцедуpы readp(), writep()*/ #include <stdio.h> /*сохpаняет число считанных и записанных байтов, на случай, если эти значения понадобятся (cм. функцию serveur) */ int nbcarlu; /*число считанных байт */ int nbcarecrit; /*число записанных байт */
/*пpоцедуpа считывания из сокета */ readp(sock, buf, n) int *sock; /*дескpиптоp сокета */ char *buf; /*буфеp */ unsigned int n; /*число записываемых байт */ { int nlu; nlu = read(*sock, buf, n); nbcarlu = nlu; /*если ни один символ не считан, пpисваиваем код ошибки */ if (nlu == 0) nlu = -1 ; return nlu; }
/*пpоцедуpа записи в сокет */ writep(sock, buf, n) int *sock; /*дескpиптоp сокета */ char *buf; /*буфеp */ unsihned int n; /*число записываемых байт */ { int necr; necr = write(*sock, buf, n); nbcarecrit = necr; /*если ни один символ не записан, пpисваиваем код ошибки */ if (necr == 0) necr= -1; return necr; }
IP представляют собой два фактических
UNIX и TCP/ IP представляют собой два фактических стандарта.
Основной активной единицей системы UNIX является процесс. Процессы создаются системным вызовом fork (), идентифициру- ются номером PID и принадлежат группе процессов. Процессу или группе процессов можно послать сигнал, являю- щийся программным прерыванием. Необходимо отличать вводы-выводы в режиме буферизации (ис- пользование стандартной библиотеки Си) и вводы выводы без буферизации (использование библиотеки UNIX). Протоколы TCP/IP предлагают два вида транспортных услуг:
- TCP/IP: с установлением логического соединения, позволяющий вести надежный обмен байтовыми потоками;
- UDP: без установления логического соединения, позволяющий вести ненадежный обмен сообщениями. Служба определяется номером порта (идентификатор с целым значением).
Для установления связи с удаленной службой необходимо определить или знать адрес Internet удаленной машины и номер порта службы. TCP включает в себя буферизации.БИБЛИОГРАФИЯ
Источником вдохновения при написании данной главы служила [STEVENS 90].
Для тех, кто хотел бы узнать побольше о концепциях и реали- зации UNIX в качестве справочных руководств рекомендуется [BACH 89] и [LEFFLER 89].
Описанию основных понятий UNIX посвящено довольно много руководств :
[KERNIGHAN 86],[RIFFLET 89],[ROCKIND 88],[RIFFLET 90],[CURRY 90] ...
Что касается TCP/IP - то, в качестве введения можно использовать RFC

Как осуществить выбор из различных внутрисистемных IPC? Большинство механизмов поддерживают работу в стиле "производитель-потребитель" (программные каналы, именованные программные каналы, файлы-сообщения). Только общая память обеспечивает неразрушающее считывание. Часто бывает достаточно именованных программных каналов (самых простых в пользовании IPC). Файлы-сообщения обеспечивают возможность отбора по типу. Использование общей памяти следует оставить для случаев, когда это необходимо из соображений эффективности. Запуск удаленного процесса можно осуществить с помощью функций system (), popen () или rexec ().
Сокеты представляют собой интерфейс входа в сеть - надстройку транспортной службы. Термин "сокет" обозначает одновременно библиотеку функций и точку входа в канал связи, то есть дескриптор, полученный посредством примитива socket (). Программирование сокетов заключается в комбинировании определенного числа примитивов для считывания или записи потока байтов или сообщений. Сокеты позволяют входить в сеть, как в файл. Этот интерфейс гибкий, но достаточно низкого уровня. Существуют два режима его применения, в зависимости от использования сокетов типа SOCK_STREAM или SOCK_DGRAM. В первом случае устанавливается соединение с TCP, во втором, работа идет с UDP в режиме дейтаграмм. Для упрощения программирования сокетов можно создать библиотеку более высокого уровня, позволяющего передавать простые типы данных (целые, с плавающей запятой, символы, массивы...). Можно обеспечить доступ к базе данных посредством программных продуктов, использующих сокеты (программные средства SQL), причем применение этих продуктов прозрачно для пользователя.
Как и сокет-интерфейс, библиотека TLI позволяет расширить механизмы межпроцессной коммуникации с одной машины на несколько машин, связанных в сеть. TLI представляет собой интерфейс - надстройку над транспортным уровнем, представляющий три группы примитивов:
- примитивы управления, позволяющие определение и присвоение имен точкам коммуникации и согласование опций протоколов связи;
- примитивы коммуникации с установлением соединения;
- примитивы коммуникации без установления соединения.
Ввод и вывод модулей делают механизм STREAMS хорошо приспособленным к разработке средств коммуникации и ,особенно, сете-вых протоколов. Один протокол можно легко заменить на другой, в той степени, в какой эти протоколы имеют равнозначный интерфейс и семантику услуг. Один и тот же модуль может быть повторно использован при конструировании различных служб. Библиотека TLI более полная, чем сокет-интерфейс, но и несколько более сложная в реализации. Она интересна тем, что позволяет писать программы, независимые от используемой транспортной службы. Кроме того, она освобождает программиста от системного интерфейса STREAMS и от вызовов, контролирующих протекание процесса (в частности, сигналов). Ее использование будет расширяться в зависимости от желания разработчиков соответствовать стандарту. TLI использовалась группой X/Open под именем XTI (X/Open Transport Interface).
NFS обеспечивает прозрачный доступ к удаленным файловым сис- темам, расположенным на разнотиповых машинах. NFS использует RPC (Remote Procedure Call) для обеспечения диалога между кли- ентом и сервером и XDR (eXternal Data Representation) для об- мена данными, связанными с протоколом. Что касается нижних уровней протокола, текущие версии NFS используют UDP. Производительность : от 200 до 600 К/сек при чтении и от 50 до 100 К/сек при записи.
Отслеживающая программа lockd позволяет управлять одновре- менным доступом к файлам или записям.
Несмотря на свои недостатки, NFS - это технологически зрелый продукт, удобный как для пользователей, так и для администраторов рабочих станций UNIX.
RFS (Remote File Sharing) - система разделения ресурсов, разработанная AT&T и используемая, в частности, фирмой Sun. RFS позволяет обрабатывать файлы и/или периферийные устройства (кассетные накопители,принтеры,модемы ...), расположенные на удаленных машинах так, как если бы они были локальными. Кроме того, RFS позволяет разделять специальные файлы UNIX (именованные каналы), которые можно использовать для взаимодействия двух удаленных процессов в сети. По сравнению с NFS, RFS имеет то преимущество, что позволяет разделять периферийные устройства и специальные файлы. Кроме того, RFS, в отличие от NFS, адресует устройства не физически, а по имени. Сервер имен преобразует имя в адрес. С другой стороны, восстановление в случае сбоя является менее тонким, а производительность более низкой (при чтении), чем у NFS. RFS, таким образом, можно использовать в качестве дополнения к NFS. Эти два продукта могут сосуществовать в одной системе
X Window - это распределенный, многооконный, графический интерфейс пользователя, очень распространенный в среде пользователей UNIX. Механизмы реализации используют модель клиент-сервер и асинхронные коммуникации. Клиент - это прикладная программа. Сервер - это программа, которая контролирует и управляет интерфейсом изображения (дисплеем). Она, таким образом, отвечает за вывод на экран, управление мышкой и клавиатурой и за отслеживанием действий пользователя.
X Window - это мощное инструментальное средство, позволяющее разрабатывать прикладные программы. Прикладные программы могут, к примеру, выполняться на обрабатывающем сервере (сервере вычислений) и управлять выводом изображений на экран и взаимодействием с пользователем на графической рабочей станции.
X Window - используется для управления двумерной графикой. Использовать третье измерение позволяет РЕХ. РЕХ предлагает те же возможности, что и X Window, а кроме того дополнительные возможности PHIGS 3D. В настоящее время начинают появляться реализации PEX. Так, например, X11R5 содержит PEX SI (Simple Implementation - Простая реализация), который управляет структурами PHIGS на сервере. Однако существуют и альтернативные возможности, позволяющие распределить трехмерные графические библиотеки.
XDR - это стандарт представления, который позволяет представить данные независимо от архитектуры машины.
Библиотека XDR - это совокупность функций языка Си, преобразующих данные из внутреннего локального представления в представление XDR и обратно. Использование XDR влечет за собой необходимость кодирования в формат XDR на станции-передатчике данных и декодирования на станции-приемнике.
Поток XDR - это последовательность байтов, где данные представлены в формате XDR. Фильтр XDR - это процедура, кодирующая или декодирующая определенный тип данных (целые, с плавающей точкой, массивы ...). Уже существующие фильтры можно комбинировать с целью создать новые. Самый простой способ создать новый фильтр для сложных данных - это использование препроцессора RPCGEN. Есть возможность комбинировать сокеты и XDR :
- поток памяти с сокетами UDP - поток записей с сокетами TCP.
Ядро системы UNIX
Ядро представляет собой активную часть операционной системы. Оно обеспечивает основные системные функции (управление памятью, управление и контроль процессов, управление файловой системой, управление вводов-выводом данных), которые позволяют процессам использовать различные возможности, предоставляемые системой.
Эксплуатация
Продукт является прозрачным для пользователя, если не счи- тать несколько специальных операций, основные из которых опи- саны в параграфе 6.3.3. Все команды "экспортирования" и "мон- тирования" выполняются при запуске системы и входят в компетенцию администраторов.
В распоряжении пользователя есть команды, позволяющие ему контролировать функционирование NFS :
- список "экспортируемых" файлов сервера : со стороны машины -клиента для вывода этой информации можно использовать ко- манду showmnt ; со стороны сервера можно использовать ко- манду exportfs или непосредственно просмотреть содержимое файла /etc/exports ;
- список файлов, "смонтированных" машиной-клиентом : можно воспользоваться командой mount без параметров. При этом выводится содержимое файла /etc/mtab.
Напоминаем, что привилегированный пользователь теряет в сети свои права, он становится "никем" ("nobody") с UID -2, если только при экспортировании не было указано противное. Таким образом, для него эксплуатация NFS не является прозрачной.
Замки на файлах и записях управляются с помощью указания в программном коде системных вызовов (lockf(),fcntl()).
Как и в случае NFS использование системы прозрачно для пользователей. Все происходит так, как если бы экспортируемые ресурсы были локальными. В распоряжении пользователя находятся команды, которые позволяют ему осуществлять некоторый контроль :
- вывод списка экспортруемых ресурсов : #nsquery
- вывод списка файлов, смонтированных на машине-клиенте : #mount
- вывод имени текущей области : #dname
- вывод имени текущего сервера области : #rfadmin
- вывод таблицы текущих соответствий UID GID между клиентами и сервером для пользователей : #idload-n
Экспресс-данные
Этот тип пересылки возможен только для сокетов в режиме логического (виртуального) соединения с помощью TCP. По умолчанию можно послать только один байт. Для передачи большего количества, необходимо использовать опцию SO_OOBINLINE, сохраняющие экспресс-данные в обычном потоке, затем вызвать ioctl () с флагом SIOCATMARK для выявления этих экспресс-данных в полученном потоке. Процесс уведомляется о прибытии экспресс-данных сигналом SIGURG.
В режиме соединения можно послать данные вне потока. Для этого, передающая машина указывает соответствующее значение в качестве параметра функции t_snd () (флаг T_EXPEDITED). У по-лучателя тот же флаг будет установлен при возврате вызова t_rcv ().
Кодирование и декодирование
Передающий процесс кодирует данные с помощью примитивов библиотеки XDR. Принимающий процесс декодирует данные. Можно использовать XDR в памяти, для файлов или в сети (Рис. 9.2.).

Рис. 9.2. Общий принцип эксплуатации XDR.
Библиотека XDR - это набор функций, написанных на языке Си, предназначенных для преобразования данных из локального представления в представление XDR и обратно.
Командный интерпретатор shell
Командный интерпретатор shell системы UNIX представляет собой программу, обеспечивающую сопряжение между пользователем и системой. Это одновременно и интерпретатор, и командный язык. Наиболее распространенными интерпретаторами shell являются: * Bourne shell: /bin/sh; * Korn shell: /bin/ksh; * C shell: /bin/csh. Будучи более мощными, чем Bourne shell, оболочки C shell и Korn shell становятся все более и более распространенными. Последовательность команд shell можно сохранить в файле, который в этом случае носит название командного файла (script).
Концепции и предлагаемые возможности
Можно определить X Window как графический многооконный расп- ределенный интерфейс. X Window определяет несколько концепций и предлагает определенный набор возможностей, который мы и рассмотрим далее.
Конфигурация на клиентах
Используемый каталог следует смонтировать,что делается либо с помощью выдаваемой "вручную" команды монтирования, либо автоматически при запуске станции.
- монтирование вручную #mount -t nfs -o опции каталог_сервер каталог_клиент где
- каталог_сервер : имя машины сервера и имя монтируемого каталога (имя каталога следует указывать полностью,начиная с корневого), в виде :имя_сервера:имя_каталога ;
- каталог_клиент : имя каталога,задаваемое полностью, начиная с корневого каталога ;
- опции : могут принимать следующие значения
- rw (read-write) или ro (read-only) : устанавливает, при необходимости, защиту (только чтение) на каталоге сер- вера ;
- suid или nosuid : указывает,выполнять или не выполнять программы с установленным битом SUID ;
- bg (background) или fg (foreground) : опция, используемая исключительно при монтировании.
В любом случае хотя бы одна попытка монтирования выполняется в режиме foreground (т.е. система не переходит к другой операции до тех пор, пока не будет завершена эта). Остальные попытки монтирования выполняются в режиме background (управление передается оператору) или foreground (в зави- симости от выбранного значения) ;
- retry=n : в случае, если первая попытка монтирования не удалась, операция повторяется еще n раз. После n+1 -й безуспешной попытки монтирование прекращается и пользователю выдается предупреждающее сообщение (mount: server non responding - сервер не отвечает).
- soft или hard ; retrans=n ; timeo = n : после монтиро- вания файловой системы, каждый запрос NFS ждет n (зна- чение timeo) десятых долей секунды. Если ответа нет, значение времени ожидания умножается на два и запрос повторяется. Если число повторений достигло значения, указанного в опции retrans=n, то в случае, если было указано значение soft, система выдает сообщение об ошибке (RPC timeout) и запрос снимается, если же файло- вая система была смонтирована с параметром hard, выда- ется предупреждающее сообщение (NFS server non responding, still trying - NFS сервер не отвечает, все еще пробую) и запрос повторяется до тех пор, пока он не завершится успехом. - intr или nointr : опция используется только в том слу- чае, если файловая система монтируется с опцией hard. Опция intr позволяет снять с клавиатуру текущую опера- цию в том случае, если сервер не отвечает ;
- rsize=n : размер блока UDP при чтении (по умолчанию, 8192 байта). Речь идет о величине кванта обмена между клиентом и сервером. - wsize=n : размер блока UDP при записи (по умолчанию, 8192 байта). Мы советуем Вам использовать следующие значения : - hard или soft : значение hard позволяет продолжить работу при сбое запроса, в отличие от значения soft. Sun советует использовать значение hard для каталогов, смонтированных в режиме записи, однако это совершенно не обязательно. Для прикладных программ, лучше всего монтировать в режиме hard. С другой стороны,для разработчиков использование значения soft более практично : оно позволяет в случае сбоя просто прекратить ошибочную команду ;
- fg : запросы на монтирование выполняются в режиме передне- го плана ;
- nosuid : файлы с установленным битом SUID не выполняются ;
- intr : текущую операцию можно прервать с клавиатуры, нажав на CONTROL C или CONTROL Z (внимание : некоторые системы устанавливают эту возможность по умолчанию). Следующие опции можно настроить в соответствии с текущими нуждами : - ro (read-only) или rw (read-write) : значение rw может привести к проблемам, связанным с целостностью информации и/или одновременного доступа к ресурсам ;
- retry (по умолчанию, 1000) : число повторений операции монтирования в случае неудачи - retrans (по умолчанию, 4) : число попыток RPC повторить запрос ;
- timeo (7 десятых секунды, по умолчанию) : время, в течение которого клиент, выдав запрос RPC, ожидает ответа сервера. Приведем пример команды mount : #mount -t nfs -o hard,bg,nosuid,intr,rw,timeo=10, retry=5 ordinfm:/home/testnfs /home/testnfs
- Автоматическое монтирование (при запуске станции) : Параметры команды mount, при этом, хранятся в файле /etc/fstab или /etc/checklist, в зависимости от версии.
Файл /etc/fstab имеет следующий формат : каталог_сервер каталог_клиент nfs опции 0 0 (значения параметров описаны выше - см. монтирование вручную)
Приведем пример файла /etc/fstab :
ordinfm:/usr/share/man /usr/share/man nfs bg,ro,hard,intr 0 0 ordinfm:/home/testnfs /home/testnfs nfs bg,rw,hard,intr 0 0
В некоторых системах существует дополнительная возможность - automount.Следящая программа automount позволяет монтировать раздел NFS только в случае его использования - при этом раздел автоматически демонтируется, если он не использовался долгое время. При этом файл /etc/fstab становится ненужным. Функцио- нирование automount задается параметрами, указываемыми в фай- лах maps.
Конфигурация на серверах
Системы экспортируемых файлов описываются в файле /etc/exports. Система файлов экспортируется в машину или группу машин (группу машин можно описать в файле /etc/netgroup). Можно, кроме того, задать права доступа к экспортируемым файлам. В системе SunOS, команда exportfs позволяет временно экспортировать систему файлов ; если выдать эту команду без параметров, она выведет список экспортированных файлов. В других системах следует модифицировать файл /etc/exports, который считывается заново при каждом очередном запросе на "монтирование".
В нашем примере, для того, чтобы экспортировать каталоги usr /share и /home, следует ввести следующие команды : #exportfs /usr/share -ro #exportfs /home -rw (значения параметров можно понять, изучив структуру файла /etc/exports).
Файл /etc/exports имеет следующую структуру :
система_файлов -опции список_клиентов где :
- система_файлов : система экспортируемых файлов или каталогов
- опции : может принимать следующие значения :
- ro : ресурсы экспортируются в режиме только чтения
- rw : ресурсы экспортируются в режиме чтения и записи
- root : клиент сохраняет права привилегированного пользователя
- noroot : клиент теряет права привилегированного пользователя
- список_клиентов : список машин-клиентов или ссылка на список машин-клиентов, указанных в файле /etc/netgroup. По умолчанию, файловая система экспортируется для всех машин в режиме чтения и записи, и клиент теряет права привилегированного пользователя.
В нашем примере файл /etc/exports может выглядеть следующим образом (предполагается, что каталог /usr/share делится между всеми машинами, а каталог /home принадлежит исключительно машине ordinaq, причем привилегированный пользователь на ней сохраняет свои права) :
/usr/share -ro /home -rw,root ordinaq